
BitMex 과거 Raw Tick Data
System Trading 시 시간 봉(차트)로 거래를 하면 소위말하는 휩소(whipsaw: 가늘고 긴 톱)에 당하기 쉽다.
그래서 Tick 차트를 활용하는 것이 좋은데, Tick 차트를 만들려면 Tick Data가 필요하다.
이것 저것 검색을 하다 보니 BitMex에서 비트코인 및 코인들의 Tick Data를 제공하고 있다는 것을 알게 되었다.
BitMex 과거 Tick Data - Link
위 주소에 접속을 해 보면 아래 처럼 2014년 11월 부터 어제까지의 Data가 List-up되어 있는 것을 볼 수 있다.
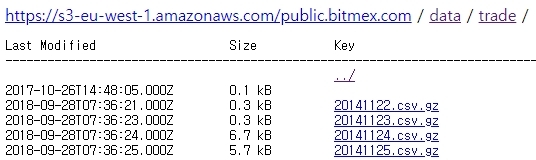
이 자료를 수동을 받으려면 몇 일이 걸릴지… 이런 작업이 또 생긴다면?…
그래서 동적 웹 크롤링 (Crawling)을 사용하려 한다.
정적 웹 크롤링 (request, beautifulsoup)의 한계
웹 크롤링을 하기 전에 크롤링을 하려는 웹 페이지의 구성을 보면,
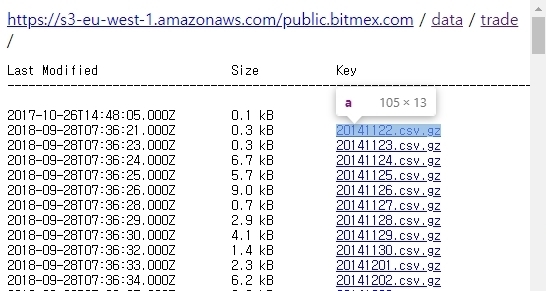
이 처럼 listing 이라는 id로 된 div tag 하위의 pre tag 안에 a tag로 link가 걸려 있다.
a tag의 href에 적힌 수많은 파일들의 링크 주소를 얻어야 tick data를 다운 받을 수 있다.
주소를 얻기 위해서 우선 requests 를 사용하여 위에 링크된 Raw tick data가 있는 Page를 확인 해 보겠다.
1
2
3
4
5
6
7
8
9
import requests
def download(url):
page = requests.get(url).text
print(page)
if __name__ == '__main__':
url = "https://public.bitmex.com/?prefix=data/trade/"
download(url)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
<body>
<div id="navigation"></div>
<div id="listing"></div>
<script type="text/javascript"
src="https://public.bitmex.com/jquery.min.js"
integrity="sha384-3ceskX3iaEnIogmQchP8opvBy3Mi7Ce34nWjpBIwVTHfGYWQS9jwHDVRnpKKHJg7"
crossorigin="anonymous"
></script>
<script type="text/javascript"
src="https://public.bitmex.com/init.js"
integrity="sha384-n0cKBy1+1+ACIC9J2XunFZItQjpIi1bilP1FCayDxybB40OcUY1ipK4Qjr856KWI"
crossorigin="anonymous"
></script>
<script type="text/javascript"
src="https://public.bitmex.com/list.js"
integrity="sha384-Rncjr7coAsbMCINMdkum6h64TPVhqlDpqulDQB/a68yABAgOU21duBLDdlm86oKP"
crossorigin="anonymous"
></script>
</body>
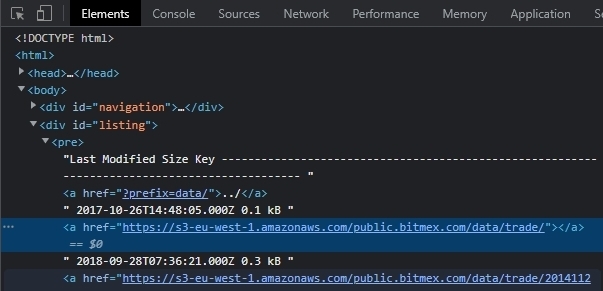
수집된 html page의 body tag를 보면 id가 listing인 div tag 하위에 아무런 tag도 존재하지 않는다.
이는 저 파일들의 링크를 웹페이지가 로딩 될때 javascript가 생성을 하게 되는데 Beautifulsoup이나
request로는 javascript가 로딩 되기 전의 html 소스를 가져오기 때문이다.
정적 웹 크롤링은 크롤링 속도가 빠르지만 동적 웹 페이지는 데이터 수집이 되지 않는다는 단점이 있다.
상황에 맞게 크롤링 라이브러리를 선택하여 사용하면 된다.
BitMex의 Coin Tick data들의 a tag는 동적으로 생성되므로 동적 웹 크롤링이 가능한 Selenium을 써야 한다.
Selenium을 이용한 동적 웹 크롤링
Selenium 설치
웹 크롤링을 할 환경에서 Selenium 패키지를 설치한다.
1
pip install selenium
아나콘다 환경을 쓰는 경우 아래와 같이 패키지를 설치한다.
1
conda install -c conda-forge selenium
Selenium은 브라우져를 컨트롤해서 Javascript를 로딩시켜 동적인 결과를 가져오는 방식이다.
Selenium에서 브라우져를 컨트롤 할 수 있게 하려면 브라우져의 드라이버를 다운받아서 사용해야 한다.
아래의 링크에서 본인이 사용하는 크롬버젼과 같은 버젼을 다운받아야 되는데 Stable Version을 다운 받으면 동일한 버젼의 드라이버를 받을 수 있을 것이다.
현재 사용중인 크롬 브라우져의 버젼 확인은 아래와 같이 확인이 가능하다.
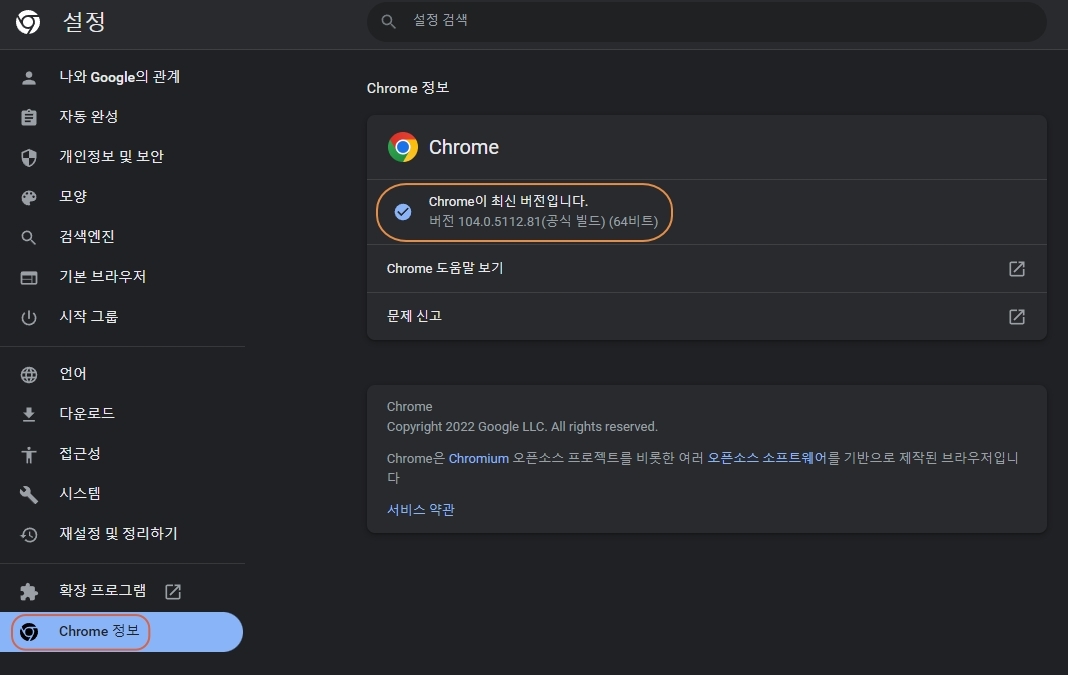
이 밖에 edge, firfox, opera 등의 브라우져 컨트롤도 가능하다.
- MS Edge Docs: https://docs.microsoft.com/en-us/microsoft-edge/webdriver-chromium/?tabs=c-sharp
- Selenium Docs: https://selenium-python.readthedocs.io/
Selenium 크롬 드라이버 객체 생성
다운받은 chromedriver.exe를 코드파일과 같은 폴더에 넣는 경우 driver = webdriver.Chrome(),
다른 폴더에 넣은 경우엔 driver = webdriver.Chrome(driver_path)로 driver 객체를 생성한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from selenium import webdriver
def get_url_links(url, driver_path=None):
if driver_path:
driver = webdriver.Chrome(driver_path) # Webdriver의 경로를 지정하는 경우
else:
driver = webdriver.Chrome() # 코드파일과 같은 폴더에 Webdriver가 있는 경우
driver.implicitly_wait(10)
# 지정된 시간인 10초 안에 페이지의 로딩이 끝나면 다음으로 넘어감.
# 지정된 시간 안에 로딩이 완료되지 않으면 Error띄움.
driver.get(url)
if __name__ == '__main__':
url = "https://public.bitmex.com/?prefix=data/trade/"
driver_path = '.\\chromedriver.exe'
get_url_links(url, driver_path)
html element parsing
얻으려는 Coin의 Tick data link는 아래의 스샷 처럼 id가 listing 인 div tag 하위의
pre tag 하위에 a tag로 이루어져 있다.
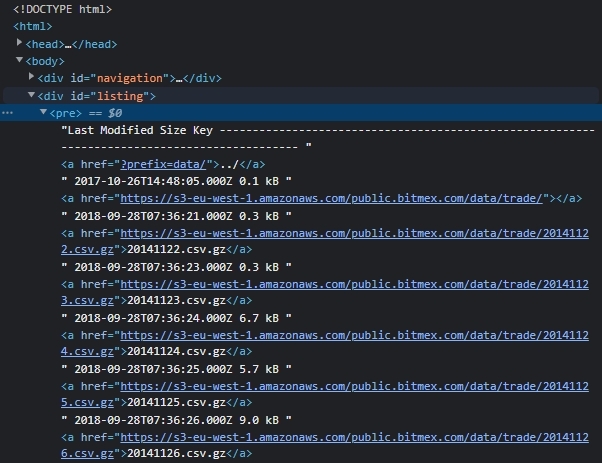
find_element_by_id('listing')로 id가 listing인 element를 얻고
find_element_by_tag_name('pre')로 pre tag 객체를 얻고
find_elements_by_tag_name('a')로 a tag인 객체들을 얻는다.
여기서 주의할 점은 a tag는 여러개로 element가 아닌 elements 복수로 써야
a tag의 객체 list를 얻을 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from selenium import webdriver
def get_url_links(url, driver_path=None, ext=''):
if driver_path:
driver = webdriver.Chrome(driver_path) # Webdriver의 경로를 지정하는 경우
else:
driver = webdriver.Chrome() # 코드파일과 같은 폴더에 Webdriver가 있는 경우
driver.implicitly_wait(10)
# 지정된 시간인 10초 안에 페이지의 로딩이 끝나면 다음으로 넘어감.
# 지정된 시간 안에 로딩이 완료되지 않으면 Error띄움.
driver.get(url)
element_id = driver.find_element_by_id('listing')
pre_tag = element_id.find_element_by_tag_name('pre')
a_tags = pre_tag.find_elements_by_tag_name('a') # a tag list를 얻음.
links = []
for a_tag in a_tags:
link = a_tag.get_attribute('href') # href의 link 주소 얻음.
if link.endswith(ext): # 확장자가 gz 인 link만 links에 append.
links.append(link)
print(links)
if __name__ == '__main__':
url = "https://public.bitmex.com/?prefix=data/trade/"
driver_path = '.\\chromedriver.exe'
get_url_links(url, driver_path, ext)
1
2
3
4
5
6
7
...
'https://s3-eu-west-1.amazonaws.com/public.bitmex.com/data/trade/20220809.csv.gz',
'https://s3-eu-west-1.amazonaws.com/public.bitmex.com/data/trade/20220810.csv.gz',
'https://s3-eu-west-1.amazonaws.com/public.bitmex.com/data/trade/20220811.csv.gz',
'https://s3-eu-west-1.amazonaws.com/public.bitmex.com/data/trade/20220812.csv.gz',
'https://s3-eu-west-1.amazonaws.com/public.bitmex.com/data/trade/20220813.csv.gz']
드디어 원하는 Coin들의 tick data link의 list를 얻었다~😊
얻은 link를 일괄 다운로드 하는 방법은 다음의 링크 참조:
https://pioneergu.github.io/posts/tick-data-download/